
Improving the generalization capabilities of general-purpose robotic agents has long been a significant challenge actively pursued by research communities. Existing approaches often rely on collecting large-scale real-world robotic data, such as the RT-1 dataset. However, these approaches typically suffer from low efficiency, limiting their capability in open-domain scenarios with new objects, and diverse backgrounds. In this paper, we propose a novel paradigm that effectively leverages language-grounded segmentation masks generated by state-of-the-art foundation models, to address a wide range of pick-and-place robot manipulation tasks in everyday scenarios. By integrating precise semantics and geometries conveyed from masks into our multi-view policy model, our approach can perceive accurate object poses and enable sample-efficient learning. Besides, such design facilitates effective generalization for grasping new objects with similar shapes observed during training. Our approach consists of two distinct steps. First, we introduce a series of foundation models to accurately ground natural language demands across multiple tasks. Second, we develop a Multi-modal Multi-view Policy Model that incorporates inputs such as RGB images, semantic masks, and robot proprioception states to jointly predict precise and executable robot actions. Extensive real-world experiments conducted on a Franka Emika robot arm validate the effectiveness of our proposed paradigm. Real-world demos are shown in YouTube/Bilibili.
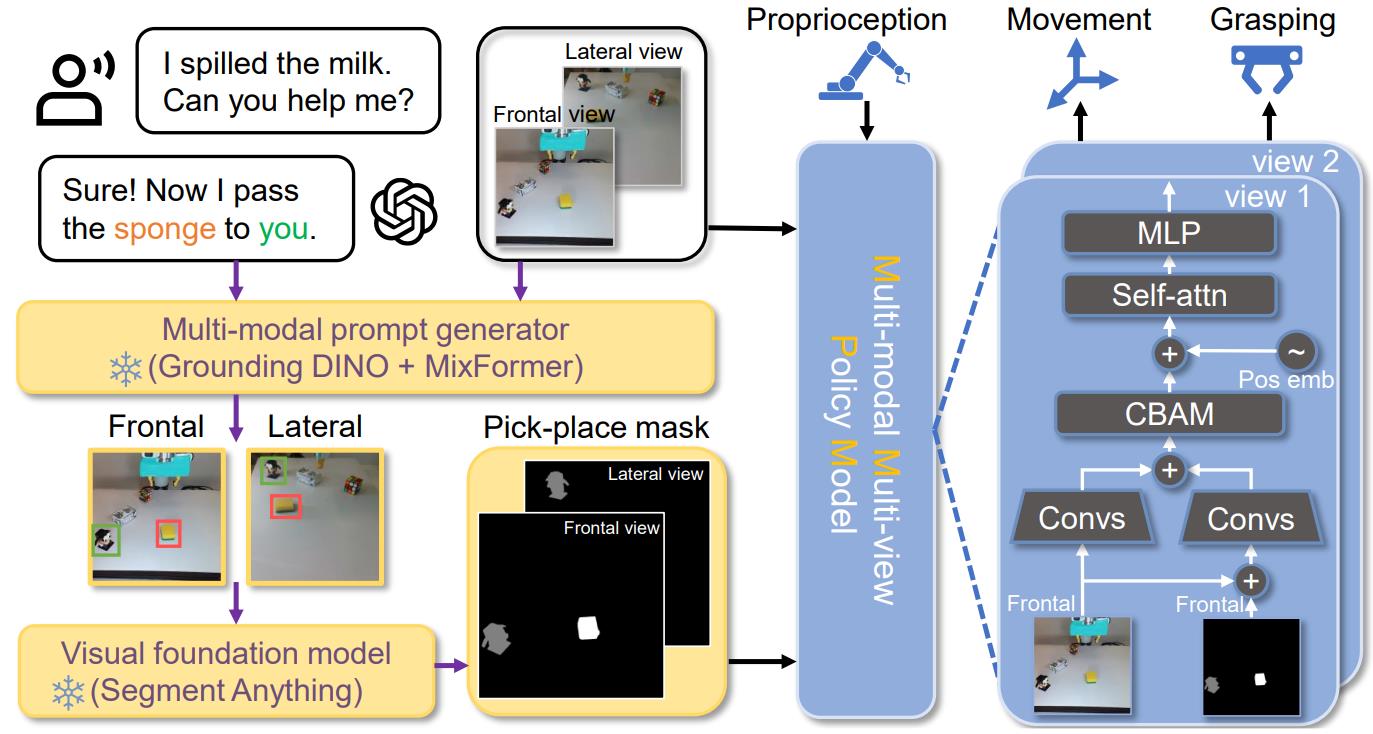
Our model comprises four components: (1) GPT-4 interprets objects for pick-and-place tasks based on human instructions and observations. (2) A multi-modal prompt generator, comprising object detection and tracking models, transforms input images and object tags into accurate bounding box trajectories. (3) The Segment Anything model, which uses bounding boxes to segment objects and generate task-focused masks for pick-and-place positions. (4) A tunable Multi-modal Multi-view Policy Model that processes images, segmentation masks, and robot proprioception to determine grasping actions. Purple and black arrows represent cognition and control dataflow, respectively.

(a): Overview of our workstation, which has a robotic arm, a frontal view camera, and a lateral view camera. (b): All the 26 seen objects. (c): All the 22 unseen objects. (d): A challenging background with complex texture for new background evaluation.

Through the ablation experiment, we draw the conclusion that: a) Segmentation mask is more effective than bounding box for action prediction. b) Tracking is more robust for prompt generation than frame-by-frame detection. c) Multi-view fusion is more beneficial compared to single view.Multi-view fusion is more beneficial compared to single view. d) Having a separate RGB branch is beneficial.
@article{yang2023pave,
title={Pave the Way to Grasp Anything: Transferring Foundation Models for Universal Pick-Place Robots},
author={Yang, Jiange and Tan, Wenhui and Jin, Chuhao and Liu, Bei and Fu, Jianlong and Song, Ruihua and Wang, Limin},
journal={arXiv preprint arXiv:2306.05716},
year={2023}
}